
SonicSim: A customizable simulation platform
for speech processing in
moving sound source scenarios
|
|
Tsinghua University, Beijing, China
|
Introdution
We introduce SonicSim, a synthetic toolkit designed to generate highly customizable data for moving sound sources. SonicSim is developed based on the embodied AI simulation platform, Habitat-sim, supporting multi-level parameter adjustments, including scene-level, microphone-level, and source-level, thereby generating more diverse synthetic data. Leveraging SonicSim, we constructed a moving sound source benchmark dataset, SonicSet, using the LibriSpeech dataset, the Freesound Dataset 50k (FSD50K) and Free Music Archive (FMA), and 90 scenes from the Matterport3D to evaluate speech separation and enhancement models.
SonicSim Platform
SonicSet Datasets
Overview of the SonicSet dataset
An automatic simulation pipeline for moving sound sources
Example

3D Room Map
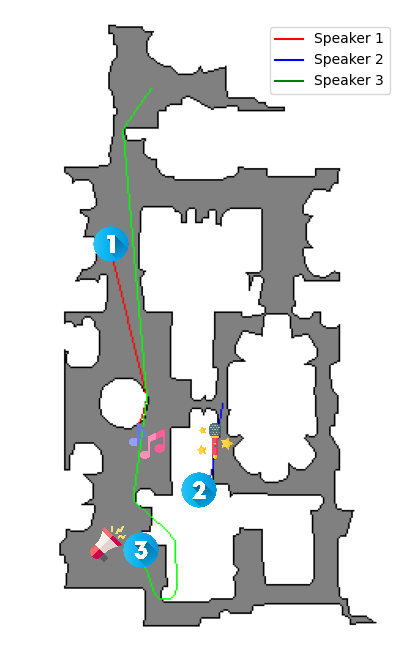
Speech Movement Trajectory
Speech Movement Trajectory 1
Speech Movement Trajectory 2
Speech Movement Trajectory 3
Music Background
Noise Background
Results
Comparison on real-recorded datasets
Speech Separation
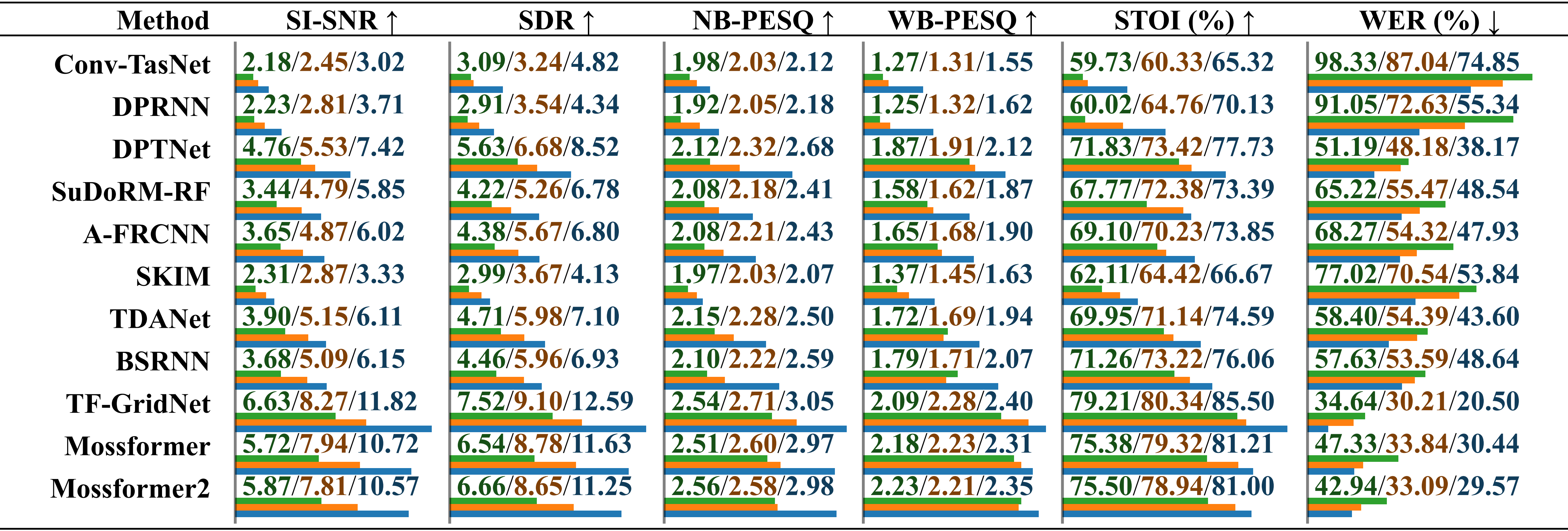
Comparative performance evaluation of models trained on different datasets using real-recorded audio with environmental noise. The results are reported separately for “trained on LRS2-2Mix”, “trained on Libri2Mix” and “trained on SonicSet”, distinguished by a slash. The relative length is indicated below the value by horizontal bars.
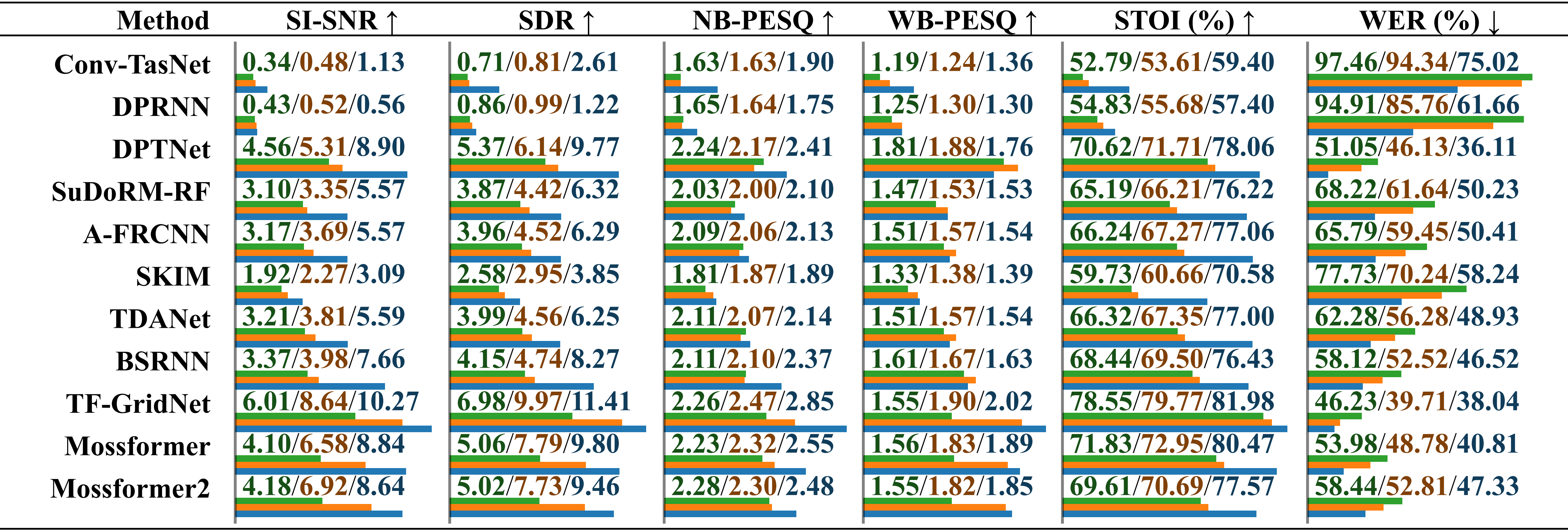
Comparative performance evaluation of models trained on different datasets using real-recorded audio with >musical noise. The results are reported separately for “trained on LRS2-2Mix”, “trained on Libri2Mix” and “trained on SonicSet”, distinguished by a slash.
Speech Enhancement
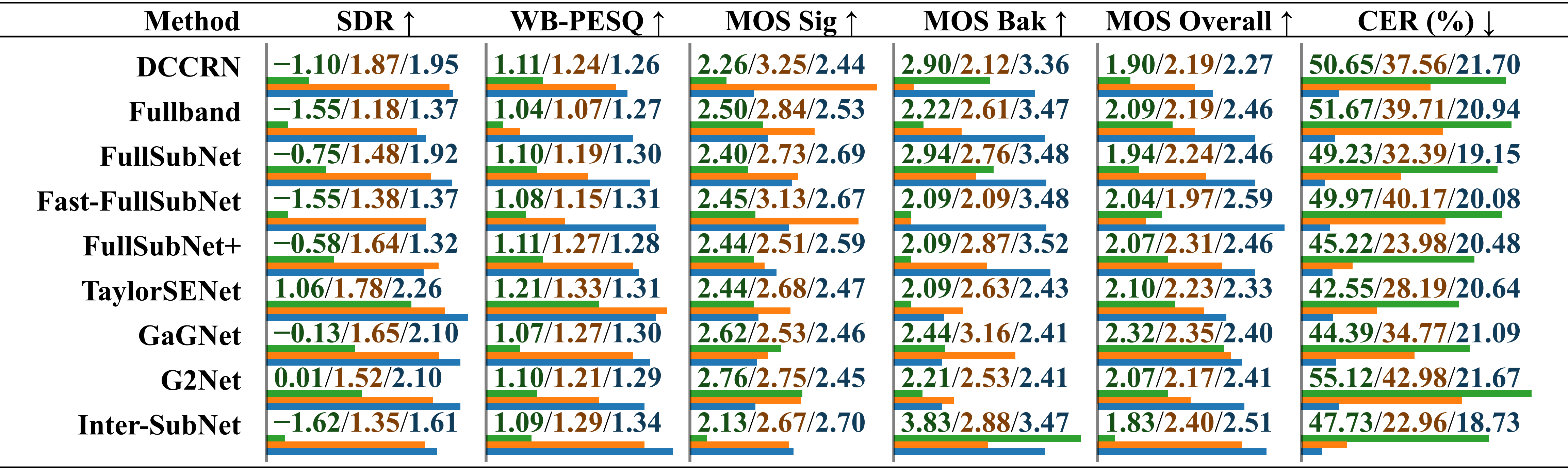
Comparative performance evaluation of models trained on different datasets using the RealMAN dataset. The results are reported separately for “trained on VoiceBank+DEMAND” , “trained on DNS Challenge” and “trained on SonicSet”, distinguished by a slash.
Comparison on SonicSet datasets
We have trained separation and enhancement models on the SonicSet dataset. The results are as follows:
Speech Separation
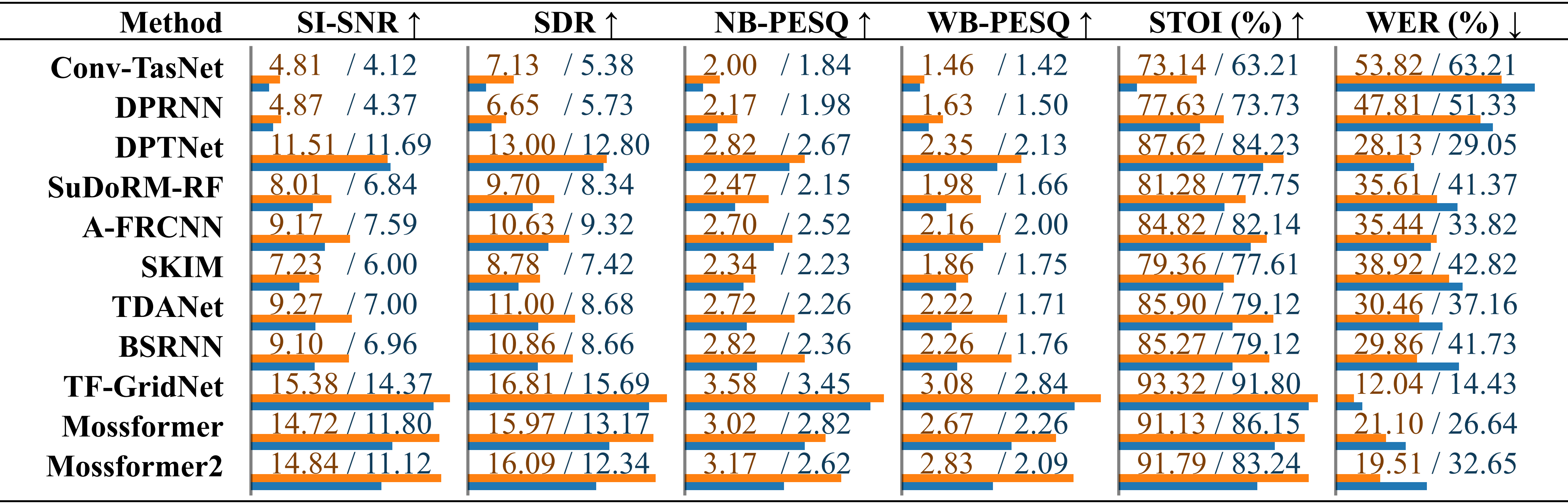
Comparison of existing speech separation methods on the SonicSet dataset. The performance of each model is listed separately for results under “environmental noise” and “musical noise”, distinguished by a slash.
Speech Enhancement
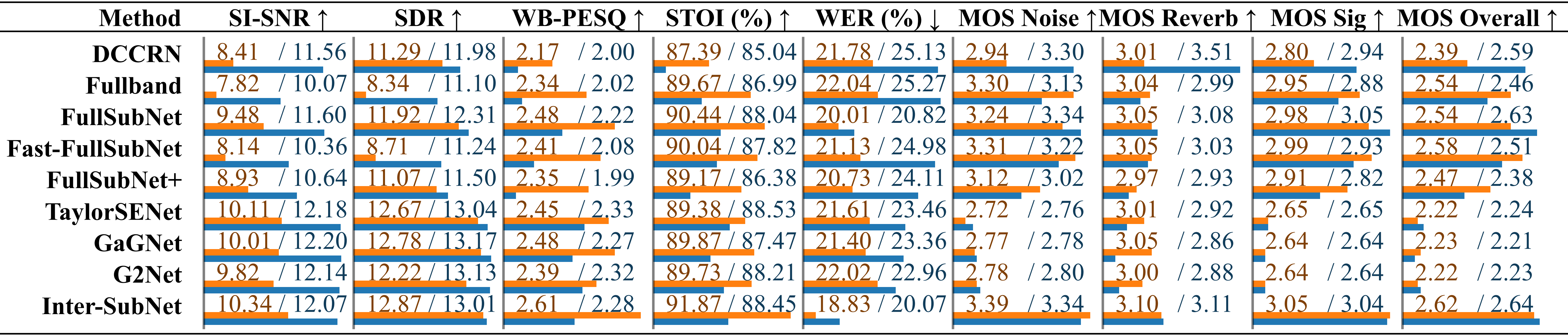
Comparison of existing speech enhancement methods on theComparison of speech enhancement methods using the SonicSet test set. The metrics are listed separately under “environmental noise” and “musical noise”, distinguished by a slash.