An efficient encoder-decoder architecture with top-down attention for speech separation
Kai Li, Runxuan Yang, Xiaolin Hu
Department of Computer Science and Technology, Tsinghua University, Beijing, China
Abstract
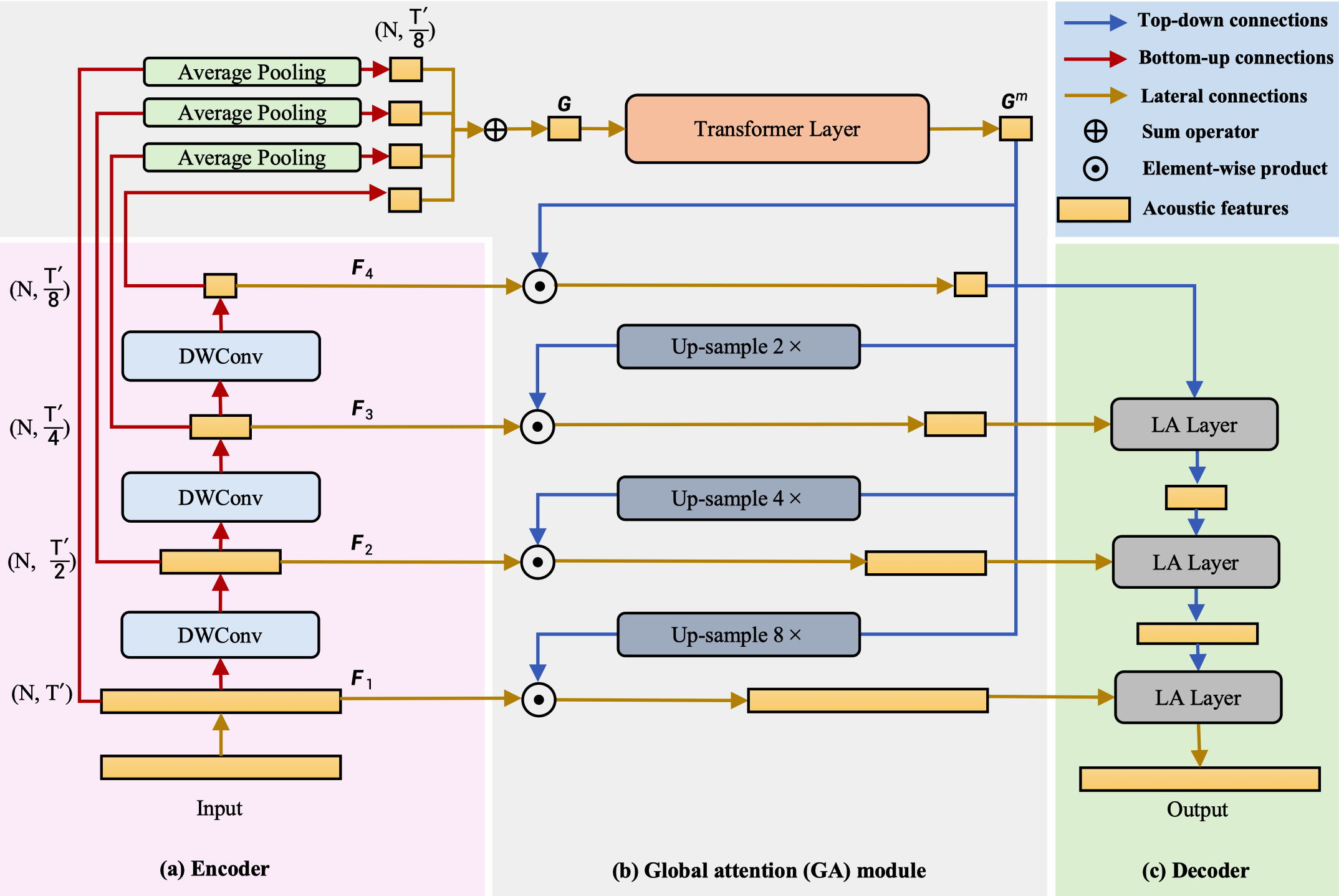
Deep neural networks have shown excellent prospects in speech separation tasks. However, finding the balance between model complexity and performance is still challenging in real-world applications. In this paper, we provide a bio-inspired efficient encoder-decoder architecture by mimicking the brain's top-down attention, called TDANet, with decreased model complexity without sacrificing performance. More specifically, the top-down attention in TDANet is extracted by the global attention (GA) module and the cascaded local attention (LA) layers. The GA module takes multi-scale acoustic features as input to extract global attention signal, which then modulates features of different scale by direct top-down connections. The LA layers use features of adjacent layers as input to extract the local attention signal, which is used to modulate the lateral input in a top-down manner. On three benchmark datasets, TDANet consistently achieved competitive separation performance with high efficiency. Specifically, TDANet's multiply-accumulate operations (MACs) are only 3.7% of A-FRCNN, and CPU inference time is only 14.8% of A-FRCNN. In addition, we propose a large-size variant: TDANet Large, which can obtain state-of-the-art results on three datasets, with MACs still only 7% of A-FRCNN and the CPU inference time is only 33% of A-FRCNN. Our study suggests that top-down attention can be a more efficient strategy for speech separation with less computational cost.
Speech Samples
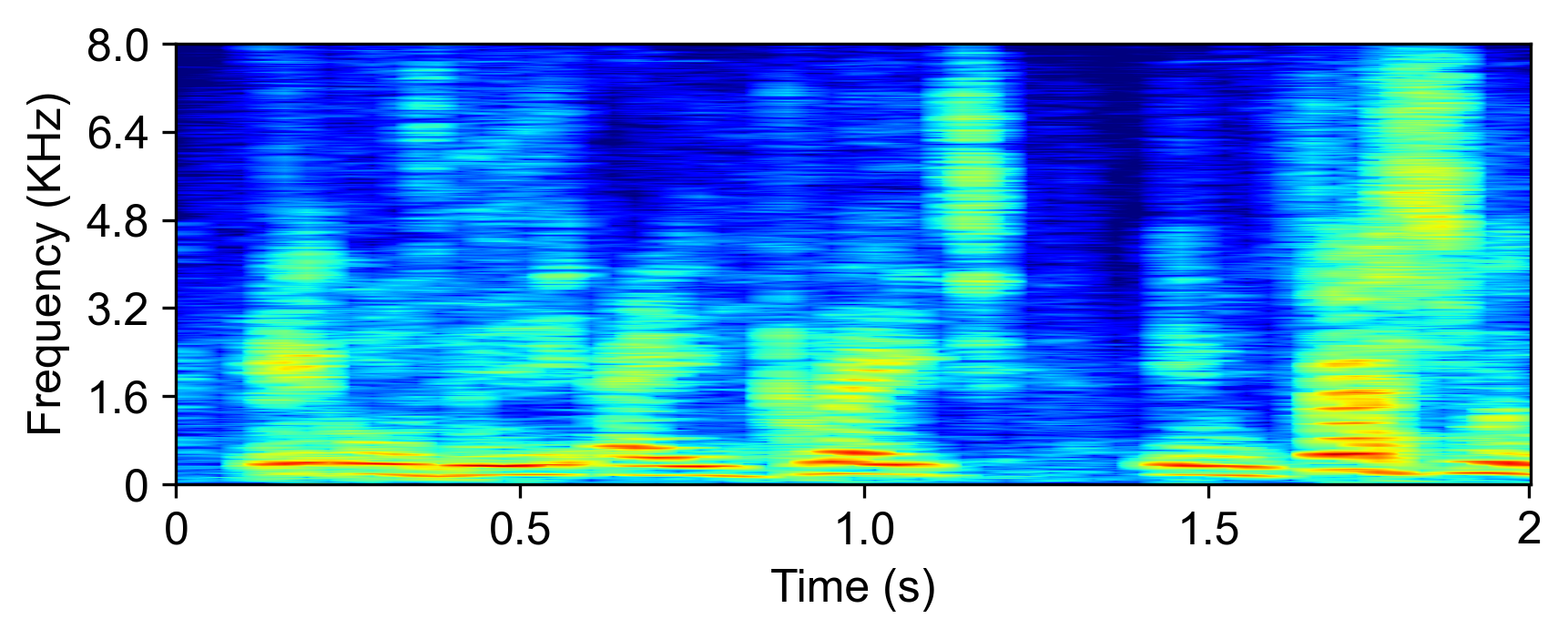
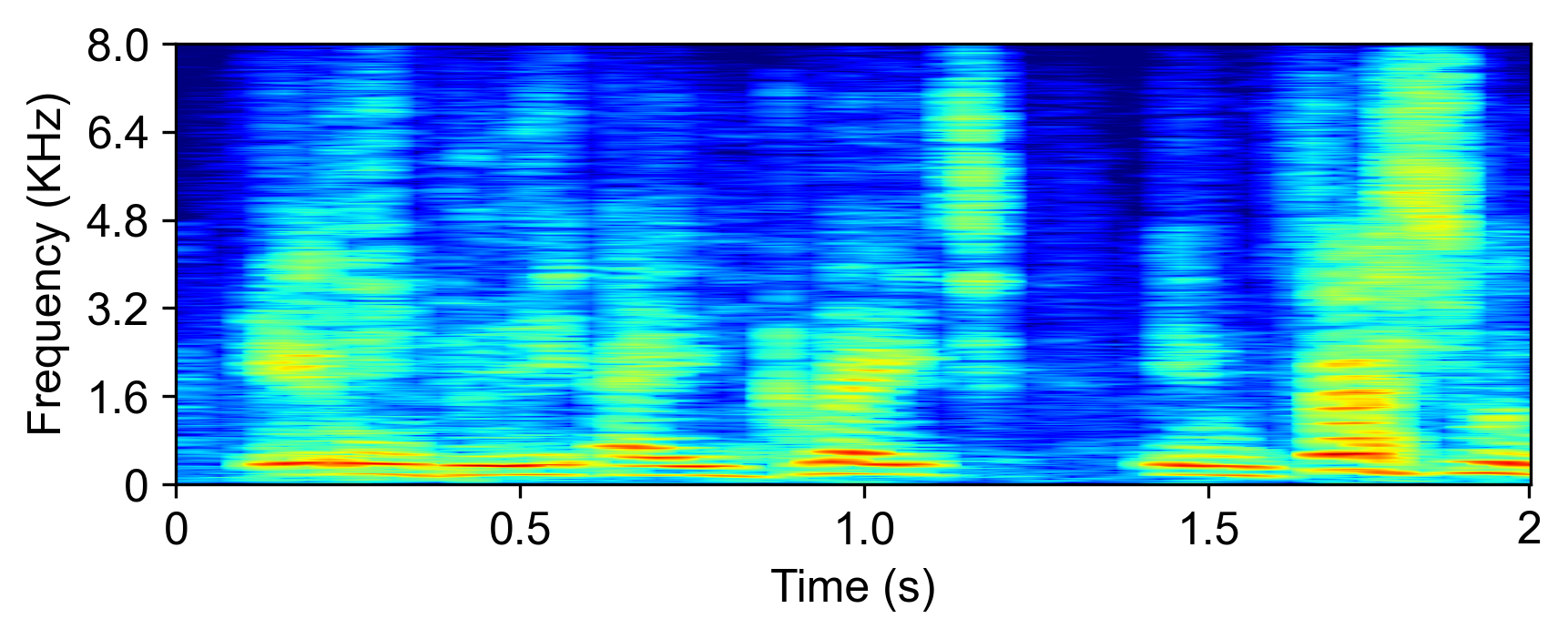
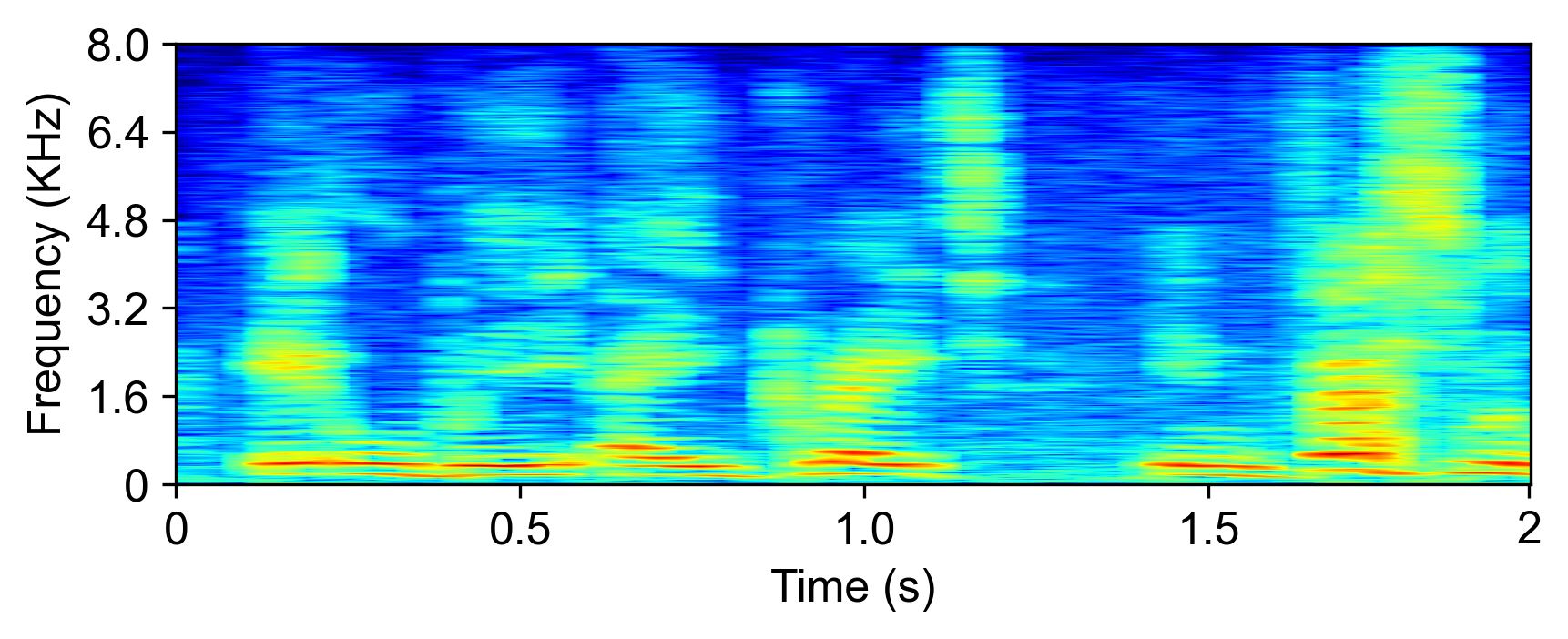
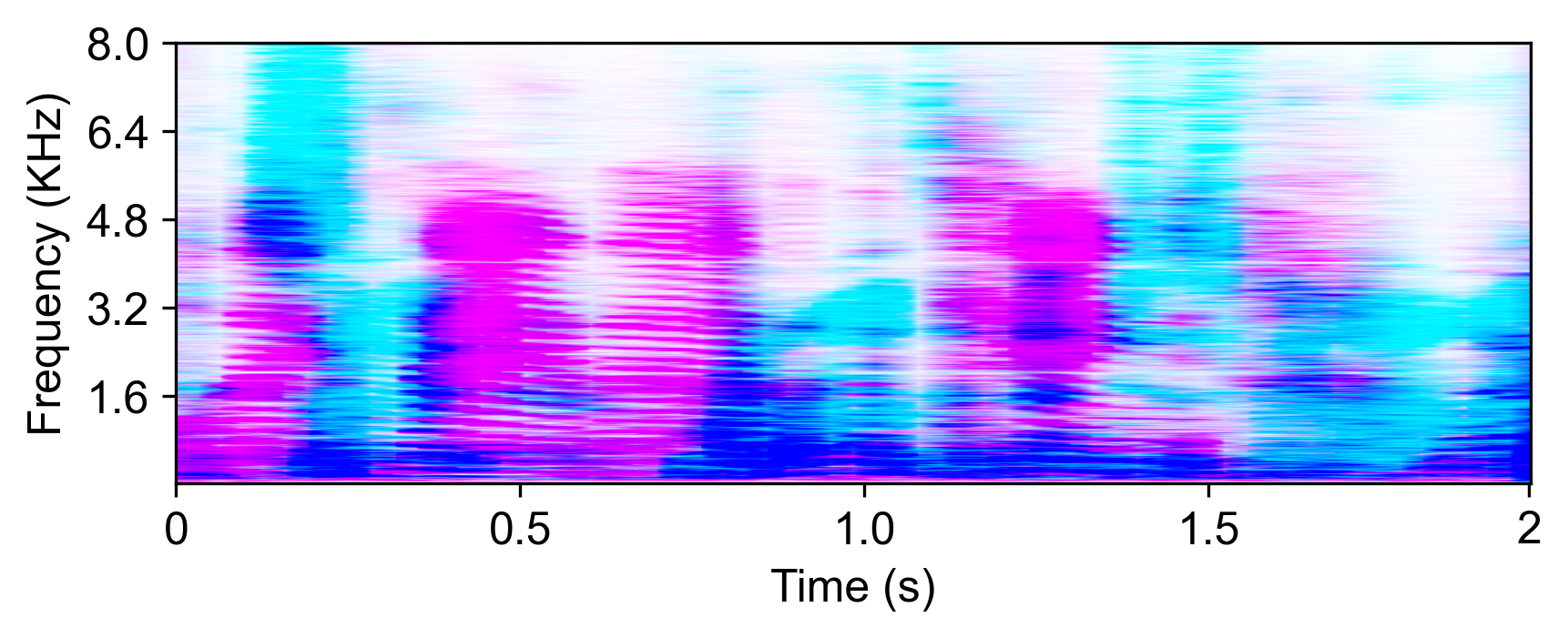
The model is evaluated with LRS2-2Mix [1]:
| Mixture input | SudoRM-RF2 | DualPathRNN3 | A-FRCNN-164 | Sepformer5 | TDANet (ours) | TDANet Large (ours) | Ground-Truth |
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
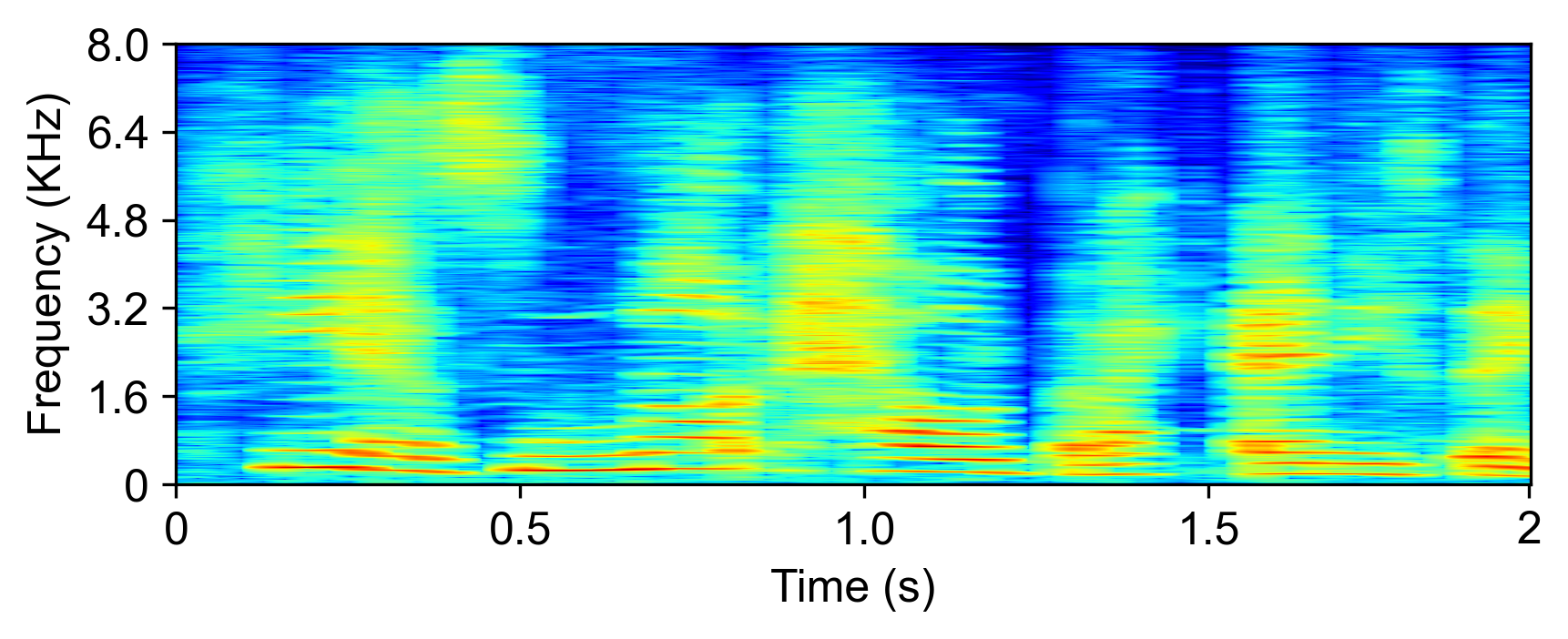
|
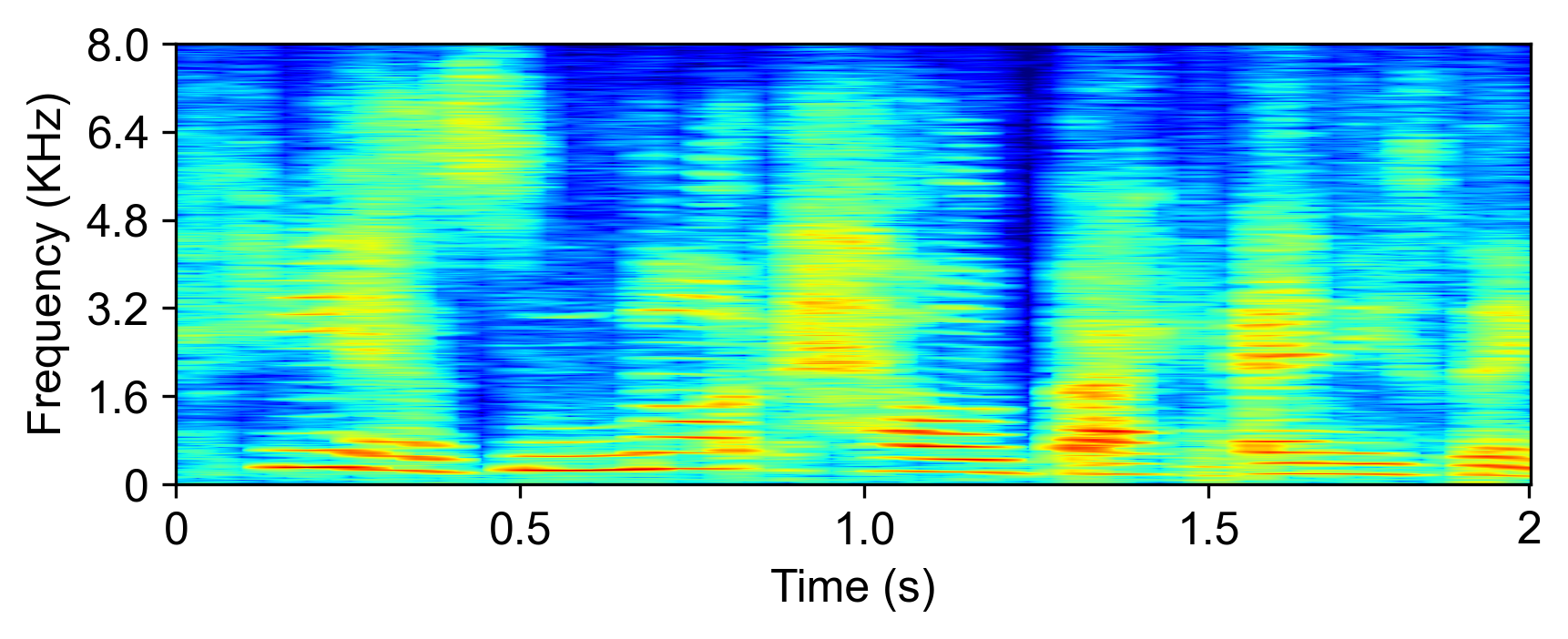
|
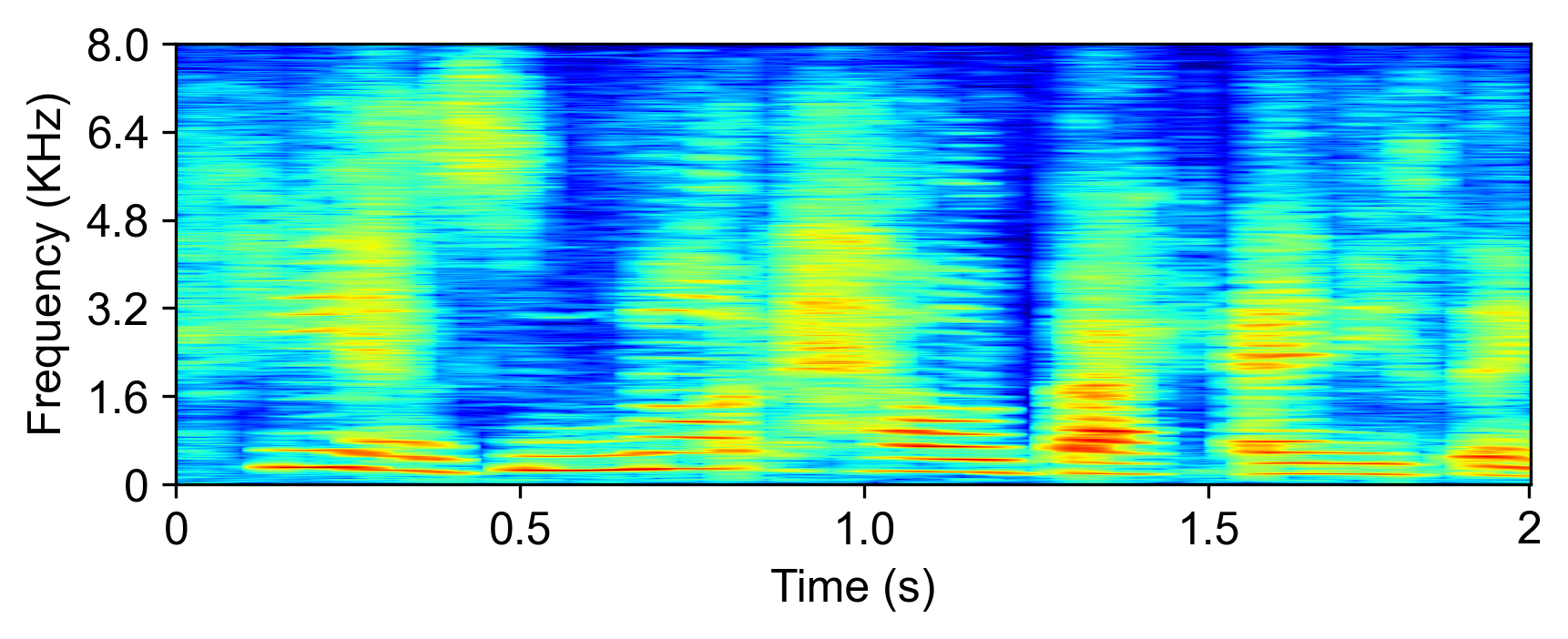
|
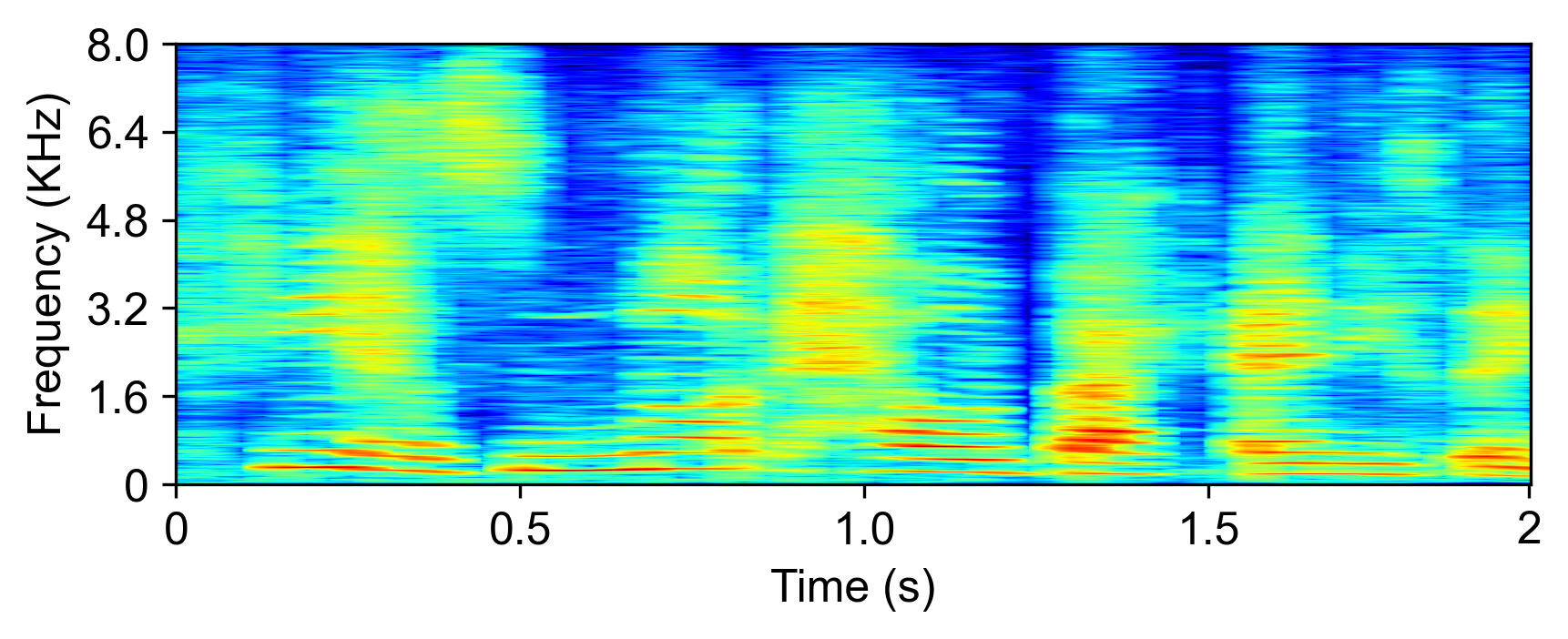
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
References
[1] Triantafyllos Afouras, Joon Son Chung, Andrew Senior, Oriol Vinyals, and Andrew Zisserman. Deep audio-visual speech recognition. IEEE transactions on pattern analysis and machine intel- ligence, 2018.
[2] Efthymios Tzinis, Zhepei Wang, and Paris Smaragdis. Sudo rm-rf: efficient networks for universal audio source separation. In IEEE 30th International Workshop on Machine Learning for Signal Processing (MLSP), pp. 1–6. IEEE, 2020.
[3] Yi Luo, Zhuo Chen, and Takuya Yoshioka. Dual-path rnn: efficient long sequence modeling for time-domain single-channel speech separation. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 46–50. IEEE, 2020.
[4] Cem Subakan, Mirco Ravanelli, Samuele Cornell, Mirko Bronzi, and Jianyuan Zhong. Attention is all you need in speech separation. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 21–25. IEEE, 2021.
[5] Xiaolin Hu, Kai Li, Weiyi Zhang, Yi Luo, Jean-Marie Lemercier, and Timo Gerkmann. Speech separation using an asynchronous fully recurrent convolutional neural network. volume 34, pp. 22509–22522, 2021.