1Tsinghua University, Beijing China
Abstract
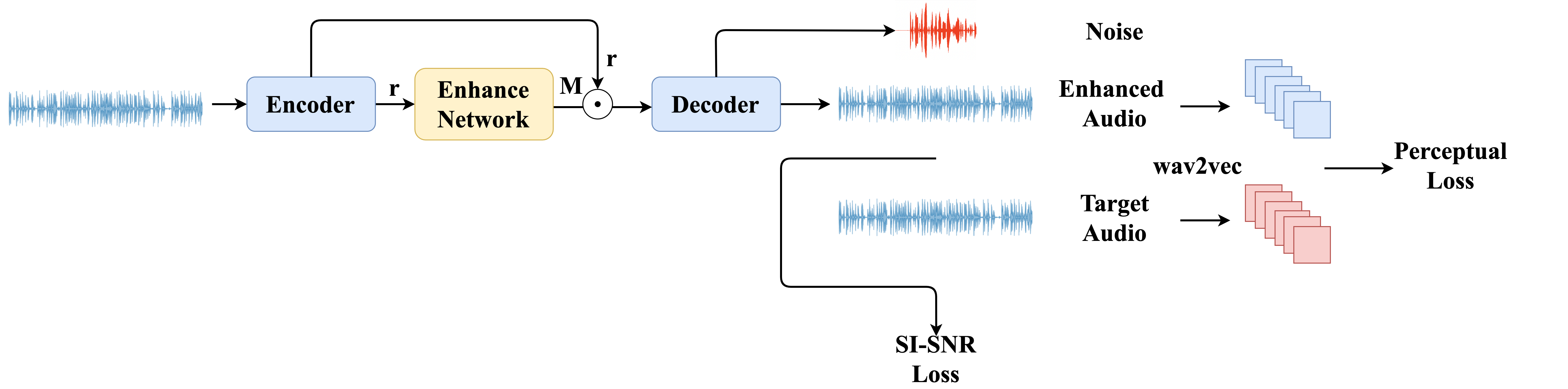
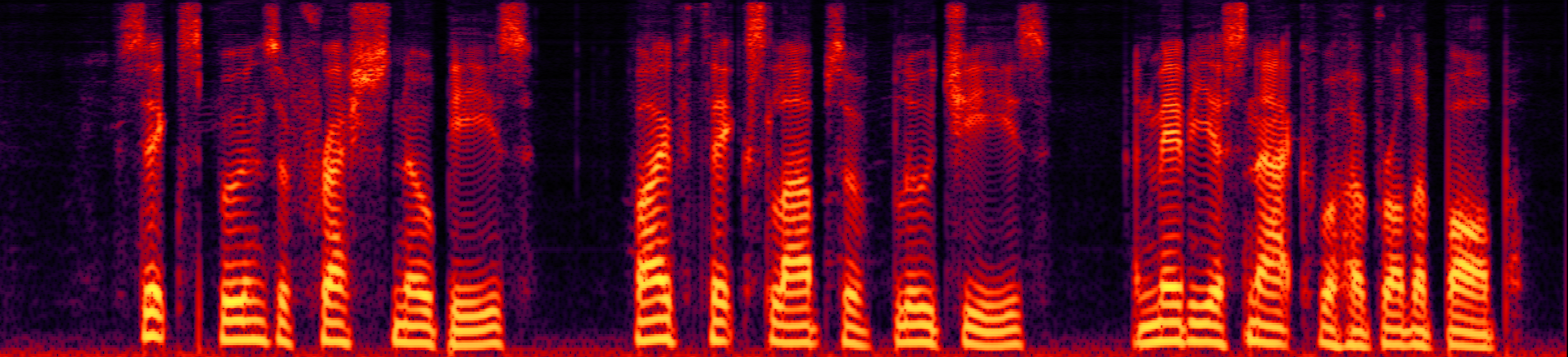
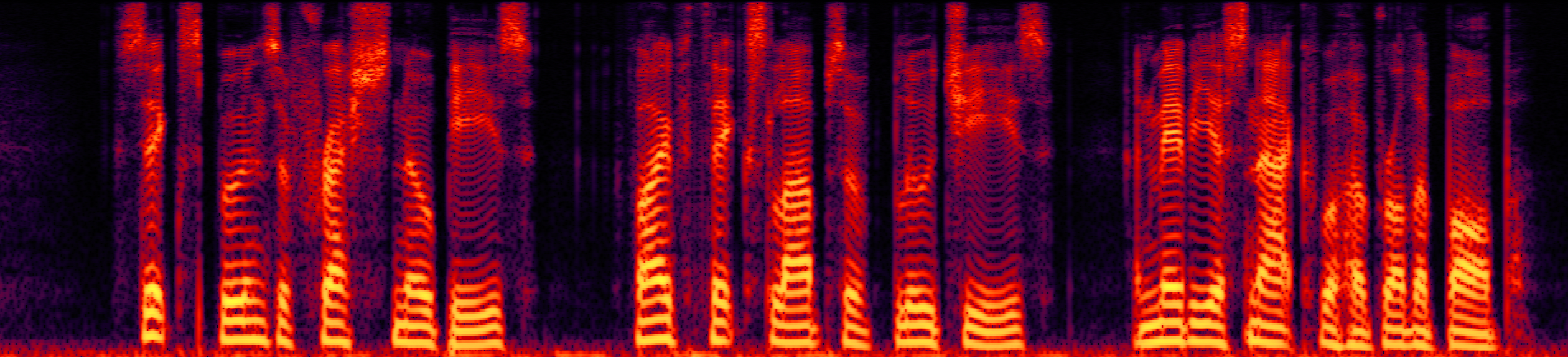
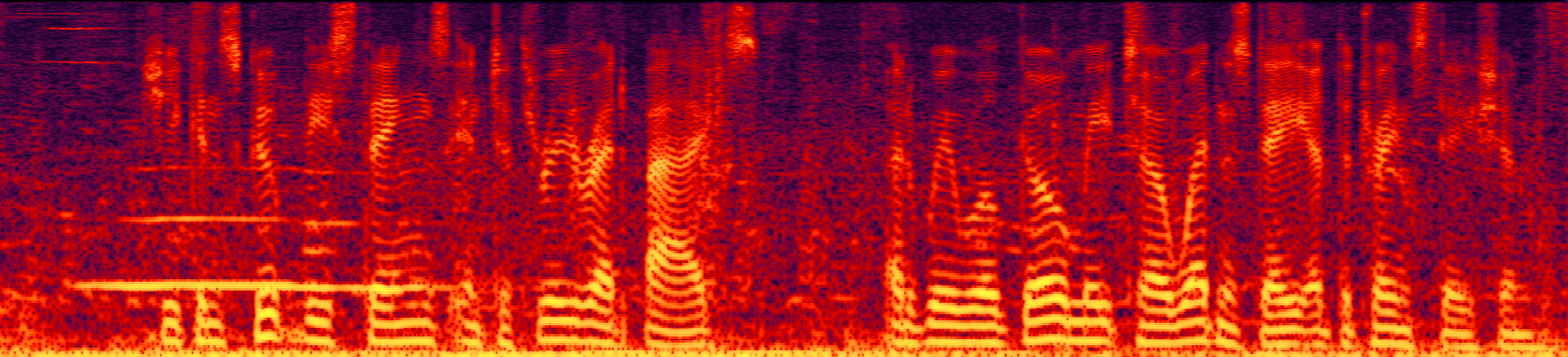
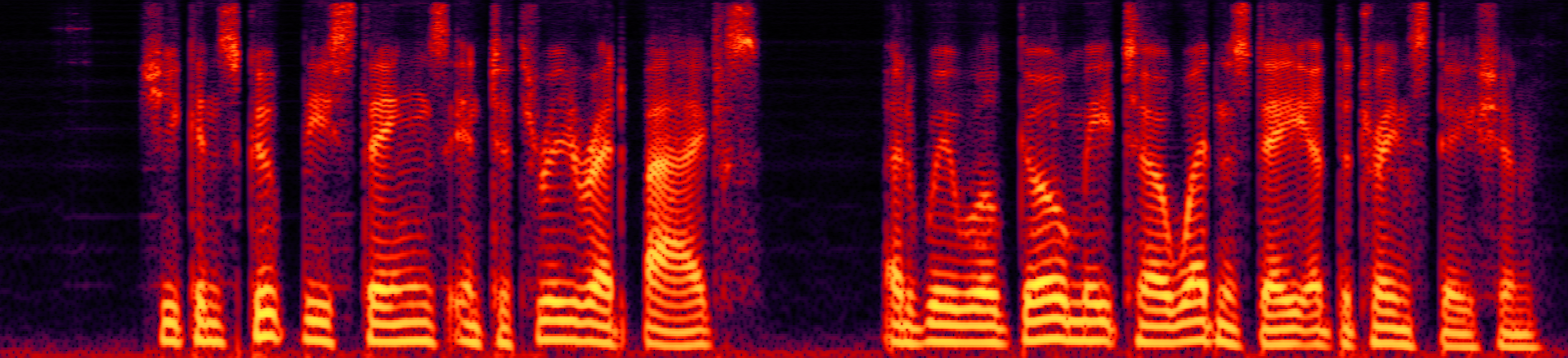
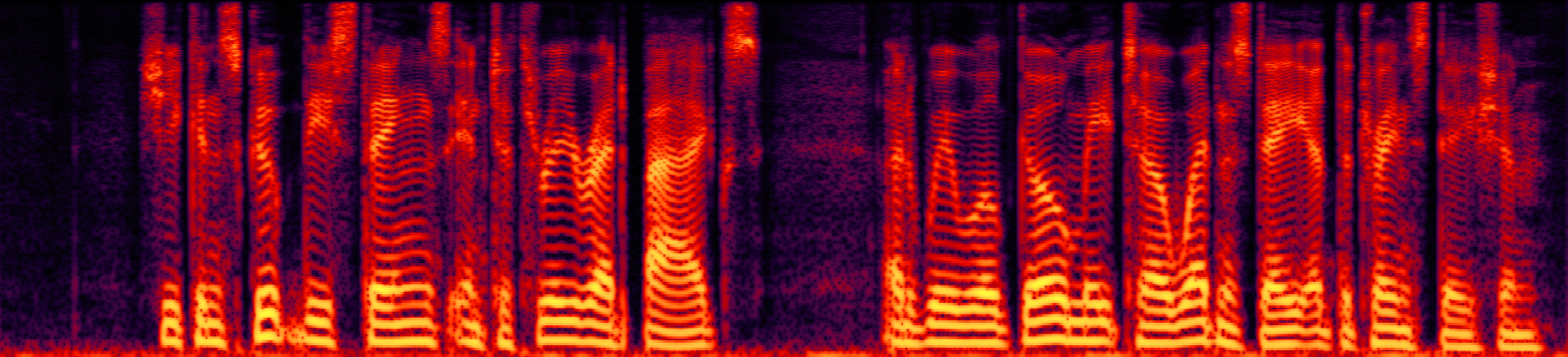
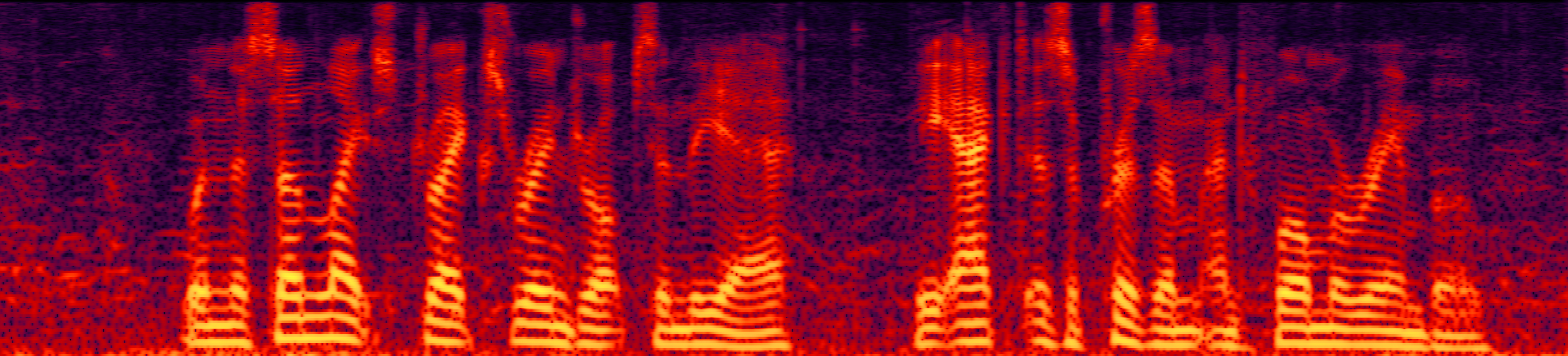
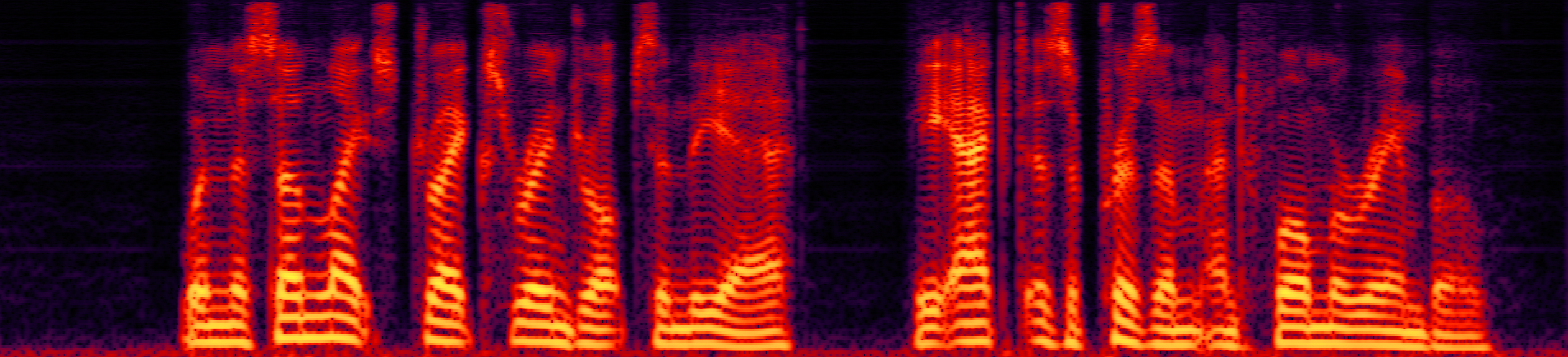
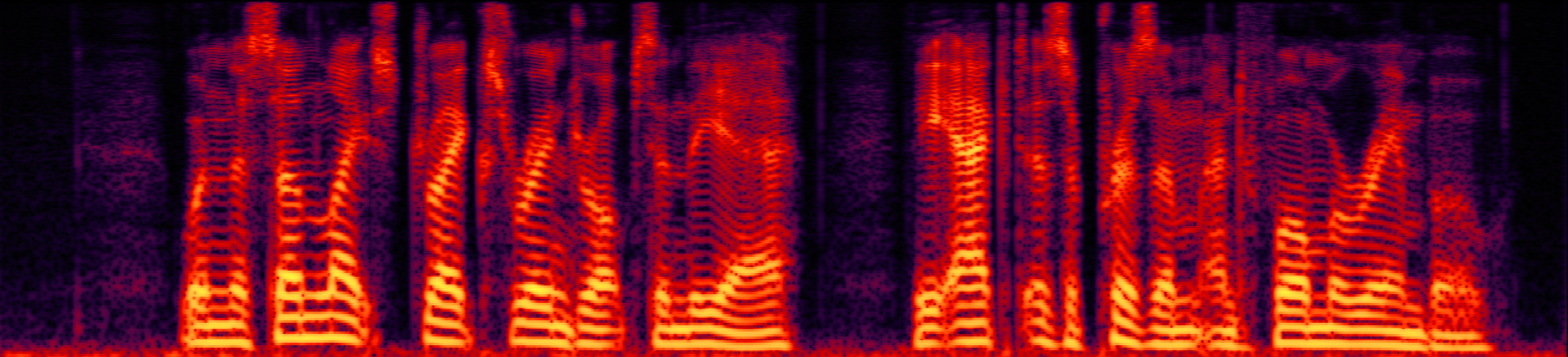
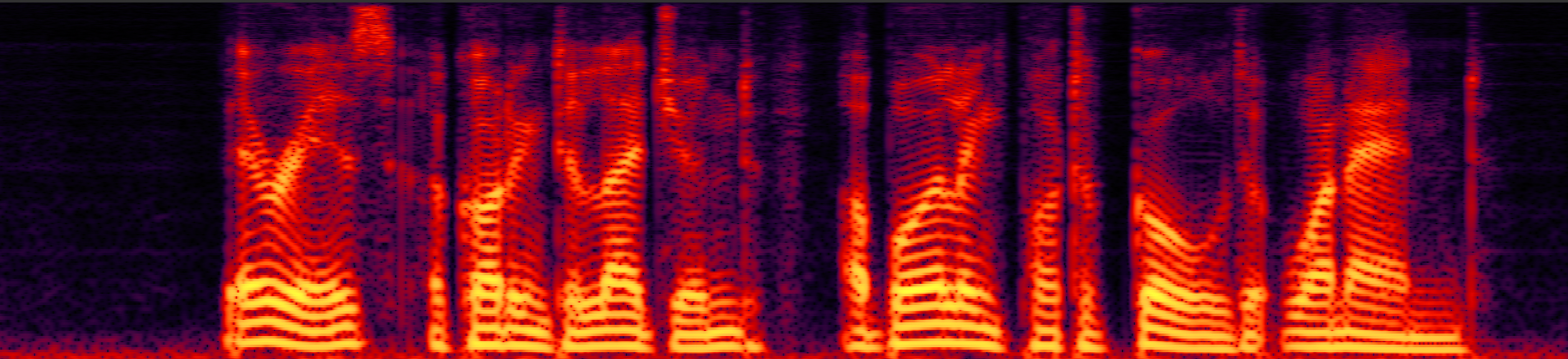
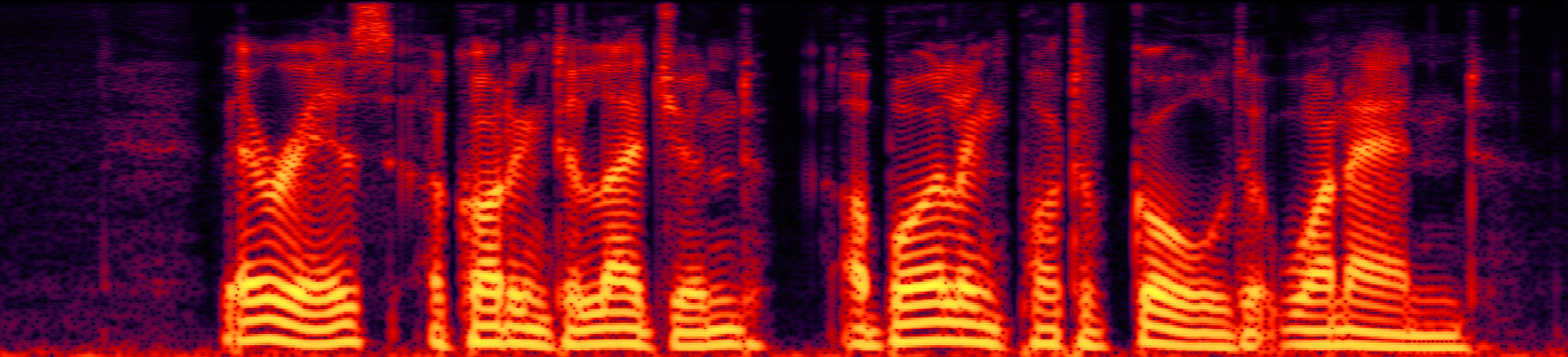
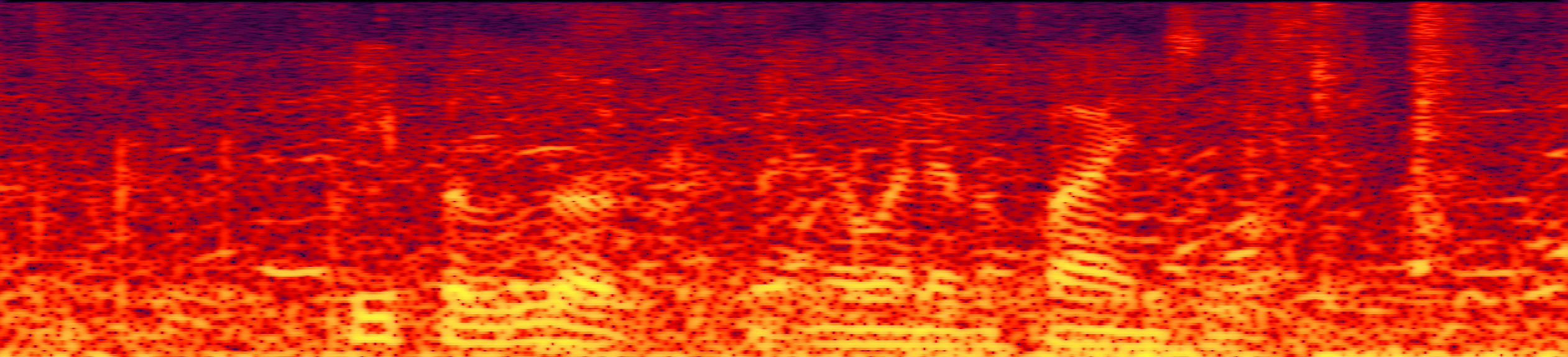
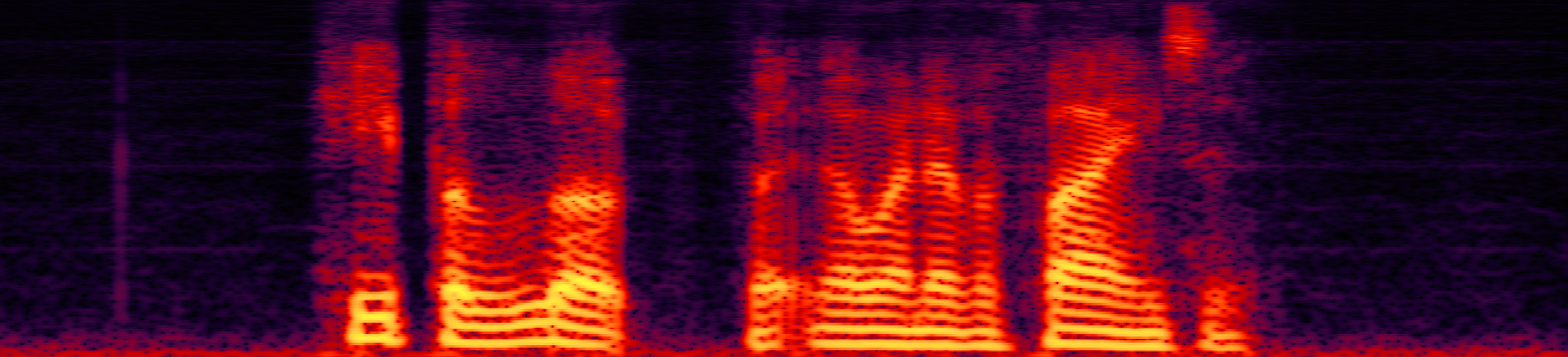
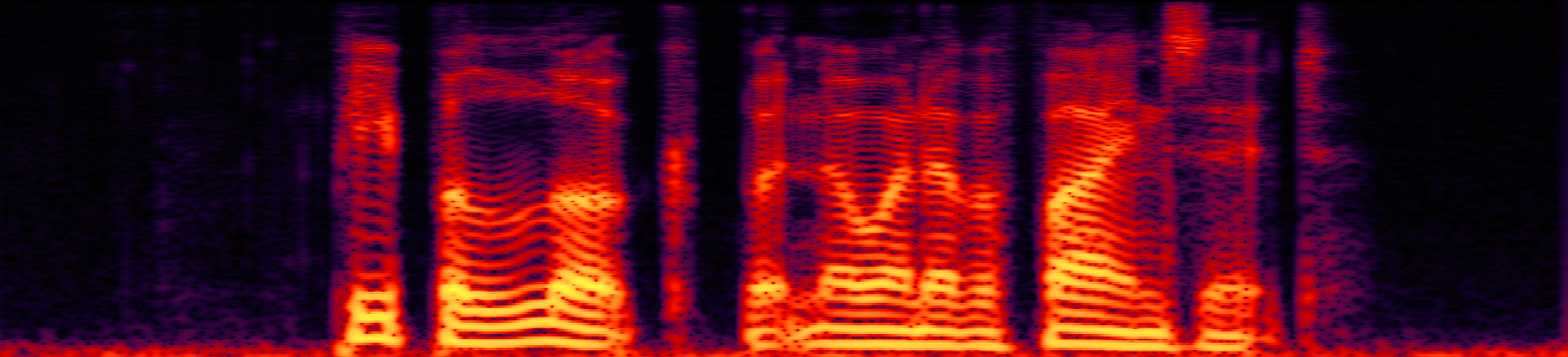
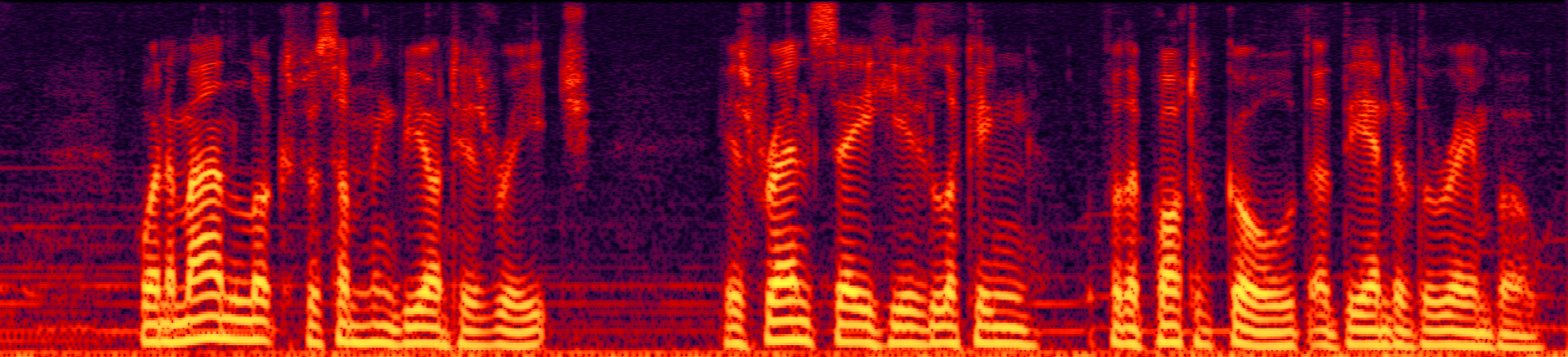
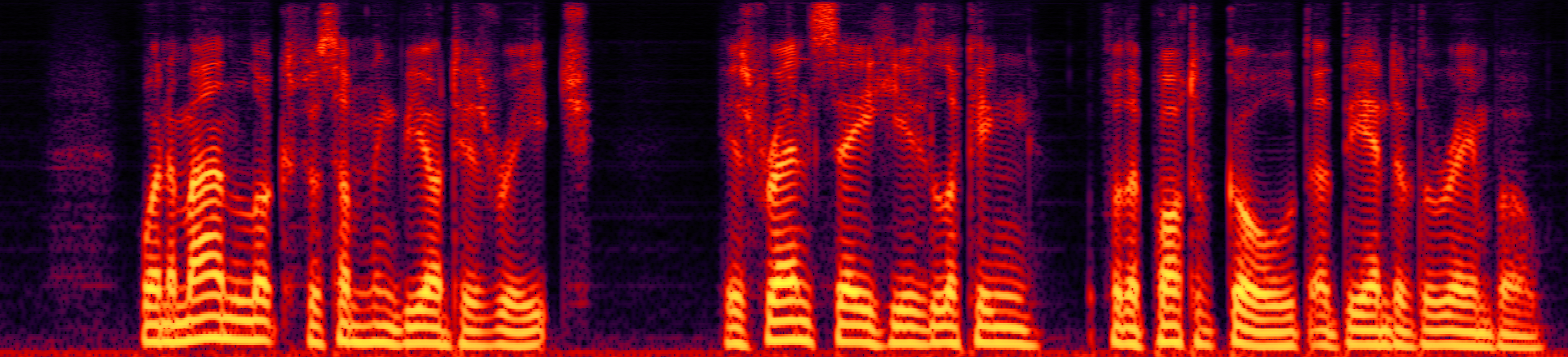
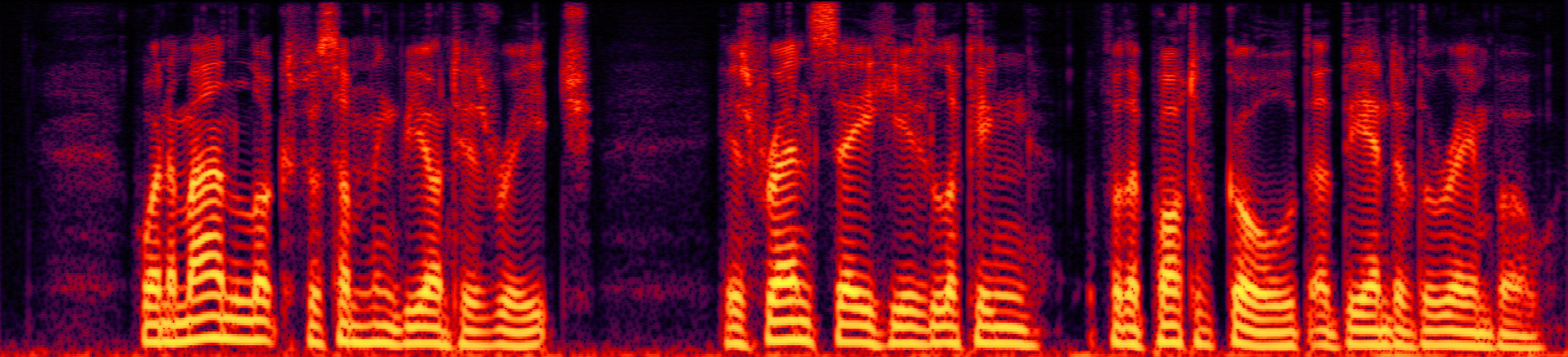
Speech enhancement (SE) aims to improve the intelligibility of speech signals in the presence of noise, which contributes to the recognition accuracy of the speech (automatic speech recognition). In this study, thanks to the successful application of our previously proposed Asynchronous Fully Recurrent Convolutional Neural Network (AFRCNN) to speech separation task showing the better separation performance, we use AFRCNN as the backbone of the speech enhancement network. Besides, in order to optimize the intelligibility of the enhanced signal, we consider speech information for training the SE model, which is computed using the potential representations of the wav2vec model. This powerful self-supervised encoder can produce abundant speech representations. We use a multi-task learning approach to train our model, employing the wasserstein distance as the distance between the speech representations and using signal level loss (SDR loss) to measure the gap between the augmented signal and the target signal. Our experimental results shown that AFRCNN-Enh can achieve the competitive performance in normalization quality and intelligibility evaluation of the Voice Bank–DEMAND dataset.
BibTeX
If you use our code or data, please cite:
@inproceedings{afrcnn2021nips,
title={Speech Separation Using an Asynchronous Fully Recurrent Convolutional Neural Network},
author={Hu, Xiaolin and Li, Kai and Zhang, Weiyi and Luo, Yi and Lemercier, Jean-Marie and Gerkmann, Timo},
booktitle={NeurIPS},
year={2021}
}