
📝 Publications
( * equal contribution, # corresponding author)
2026

DegVoC: Revisiting Neural Vocoder from a Degradation Perspective Andong Li, Tong Lei, Lingling Dai, Kai Li, Rilin Chen, Meng Yu, Xiaodong Li, Dong Yu, Chengshi Zheng. AAAI 2026. Singapore, Singapore.
- DegVoC revisits neural vocoder from a degradation perspective, proposing a novel approach for high-quality speech synthesis.

FGNet: Leveraging Feature-Guided Attention to Refine SAM2 for 3D EM Neuron Segmentation Zhenghua Li, Hang Chen, Zihao Sun, Kai Li, Xiaolin Hu. AAAI 2026. Singapore, Singapore.
- FGNet leverages feature-guided attention to refine SAM2 for accurate 3D electron microscopy neuron segmentation.

SepPrune: Structured Pruning for Efficient Deep Speech Separation Yuqi Li*, Kai Li*, Xin Yin, Zhifei Yang, Zeyu Dong, Zhengtao Yao, Haoyan Xu, Yingli Tian, Yao Lu. AAAI 2026. Singapore, Singapore.
-
SepPrune proposes structured pruning techniques for efficient deep speech separation, significantly reducing model complexity while maintaining performance.
-

2025

BAV-MossFormer2: Enhanced MossFormer2 for Binaural Audio-Visual Speech Enhancement Wenze Ren, Kai Li, Rong Chao, Junjie Li, Zilong Huang, Shafique Ahmed, You-Jin Li, Kuo-Hsuan Hung, Syu-Siang Wang, Hsin-Min Wang, Yu Tsao. AVSEC 2025. Rotterdam, Netherlands.
- BAV-MossFormer2 proposes an innovative architecture for binaural audio-visual speech enhancement, featuring an enhanced stereo audio encoder with cross-attention mechanisms for channel interaction and an adaptive dynamic fusion module for context-aware audio-visual feature fusion.

Critical Information Only: A Content Privacy-Preserving Framework for Detecting Audio Deepfakes Xinfeng Li, Yifan Zheng, Chen Yan, Kai Li, Chang Zeng, Xiaoyu Ji, Wenyuan Xu. IEEE Transactions on Dependable and Secure Computing (TDSC) 2025.
-
SafeEar is a novel framework that detects deepfake audios without accessing speech content by devising a neural audio codec into a decoupling model that separates semantic and acoustic information, using only acoustic features (e.g., prosody) for privacy-preserving detection.
-
|

MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix Ziyang Ma, Yinghao Ma, Yanqiao Zhu, Chen Yang, Yi-Wen Chao, Ruiyang Xu, Wenxi Chen, Yuanzhe Chen, Zhuo Chen, Jian Cong, Kai Li, et al. NeurIPS 2025. San Diego, California.
-
MMAR is a comprehensive benchmark designed to evaluate Audio-Language Models’ deep reasoning capabilities across multi-disciplinary audio tasks, featuring 1,000 curated audio-question-answer triplets with Chain-of-Thought rationales spanning speech, music, sound, and their mixtures.
-
|

GDSR: Global-Detail Integration Through Dual-Branch Network With Wavelet Losses for Remote Sensing Image Super-Resolution Qiwei Zhu, Kai Li, Guojing Zhang, Xiaoying Wang, Jianqiang Huang, Xilai Li. IEEE Transactions on Geoscience and Remote Sensing (TGRS) 2025.
- GDSR proposes a dual-branch network integrating global and detail information with wavelet losses for enhanced remote sensing image super-resolution


Time-Frequency-Based Attention Cache Memory Model for Real-Time Speech Separation Guo Chen*, Kai Li*, Runxuan Yang, Xiaolin Hu. ASRU 2025. Honolulu, Hawaii.
-
TFACM introduces an attention cache memory mechanism for causal speech separation, achieving comparable performance to state-of-the-art TF-GridNet-Causal with significantly lower complexity and fewer parameters through effective spatio-temporal relationship modeling.
-

A fast and lightweight model for Causal Audio-Visual Speech Separation. Wendi Sang*, Kai Li*, Runxuan Yang, Jianqiang Huang, Xiaolin Hu. ECAI 2025. Bologna, Italy.
-
Swift-Net model achieves real-time efficient speech separation by combining visual (lip reading) and audio information
-


Dynamic Dictionary Learning for Remote Sensing Image Segmentation. Xuechao Zou, Yue Li, Shun Zhang, Kai Li, Shiying Wang, Pin Tao, Junliang Xing, Congyan Lang. ICCV 2025. Honolulu, Hawaii.
-
Tackling inter-class similarity, intra-class variability, and limited dynamic adaptability to scene changes (e.g., cloud thickness) in remote sensing segmentation, we propose a dynamic dictionary learning framework with multi-stage alternating cross-attention between image features and dictionary embeddings for dynamic refinement, plus a dictionary space contrastive constraint to boost intra-class compactness and inter-class separability—outperforming state-of-the-art on coarse/fine-grained datasets, especially LoveDA and UAVid online leaderboards.
-


Knowledge Transfer and Domain Adaptation for Fine-Grained Remote Sensing Image Segmentation. Shun Zhang, Xuechao Zou, Kai Li, Congyan Lang, Shiying Wang, Pin Tao, Tengfei Cao. ICME 2025. Nantes, France.
-
This paper proposes a knowledge transfer and domain adaptation framework that leverages pretrained vision transformers to guide CNN-based models for fine-grained remote sensing image segmentation, achieving significant improvements through Feature Alignment and Feature Modulation modules.
-
|
|

SPMamba: State-space model is all you need in speech separation. Kai Li*, Guo Chen*, Runxuan Yang, Xiaolin Hu. ICME 2025. Nantes, France.
-
SPMamba revolutionizes the field of speech separation tasks by leveraging the power of Mamba in conjunction with the robust TF-GridNet infrastructure.
-
|

SonicSim: A customizable simulation platform for speech processing in moving sound source scenarios Kai Li, Wendi Sang, Chang Zeng, Guo Che, Runxuan Yang, Xiaolin Hu. ICLR 2025. Singapore EXPO.
-
SonicSim is a customizable simulation platform built on Habitat-sim, designed to generate high-fidelity, diverse synthetic data for speech separation and enhancement tasks involving moving sound sources, addressing the limitations of real-world and existing synthetic datasets in acoustic realism and scalability.
-
|
|
|

TIGER: Time-frequency Interleaved Gain Extraction and Reconstruction for Efficient Speech Separation Mohan Xu, Kai Li*, Guo Chen, Xiaolin Hu. ICLR 2025. Singapore EXPO.
-
TIGER is an efficient time-frequency domain speech separation model that significantly reduces parameters and computational costs by leveraging frequency band-split and multi-scale attention, achieving state-of-the-art performance while being highly lightweight.
-
|
|

Apollo: Band-sequence Modeling for High-Quality Audio Restoration Kai Li, Yi Luo. ICASSP 2025. Hyderabad, India.
-
Apollo is a generative model for high-sample-rate audio restoration that utilizes a frequency band split module to enhance audio quality, outperforming existing SR-GAN models in terms of restoration quality and computational efficiency.
-
|
|
2024
SafeEar: Content Privacy-Preserving Audio Deepfake Detection Xinfeng Li, Kai Li*, Yifan Zheng, Chen Yan, Xiaoyu Ji, Wenyuan Xu. CCS 2024. Salt Lake City, U.S.A.
-
SafeEar, a novel framework that aims to detect deepfake audios without relying on accessing the speech content within.
-
|
|
|

IIANet: an intra- and inter-modality attention network for audio-visual speech separation Kai Li, Runxuan Yang, Sun Fuchun, Xiaolin Hu. ICML 2024. Vienna, Austria.
-
Inspired by the cross-modal processing mechanism in the brain, we design intra- and inter-attention modules to integrate auditary and visual information for efficient speech separation. The model simulates audio-visual fusion in different levels of sensory cortical areas as well as higher association areas such as parietal cortex.
-
|
 |
|  |
| 
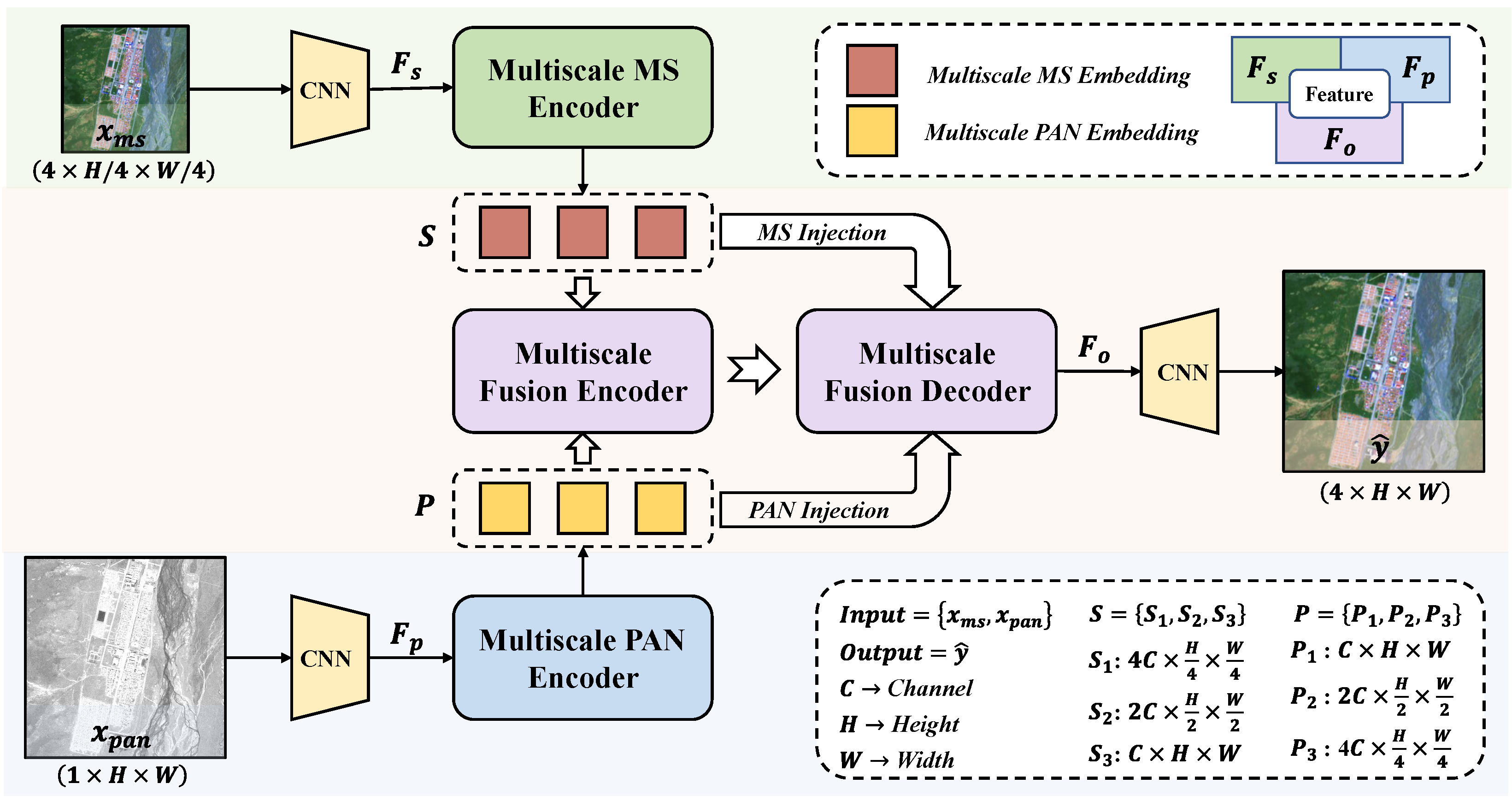
Towards Robust Pansharpening: A Large-Scale High-Resolution Multi-Scene Dataset and Novel Approach Shiying Wang, Xuechao Zou, Kai Li, Junliang Xing, Tengfei Cao, Pin Tao. Remote Sensing 2024.
-
PanBench, a high-resolution multi-scene dataset containing all mainstream satellites and comprising 5898 pairs of samples.
-
|

The sound demixing challenge 2023–Cinematic demixing track. Stefan Uhlich, Giorgio Fabbro, Masato Hirano, Shusuke Takahashi, Gordon Wichern, Jonathan Le Roux, Dipam Chakraborty, Sharada Mohanty, Kai Li, Yi Luo, Jianwei Yu, Rongzhi Gu, Roman Solovyev, Alexander Stempkovskiy, Tatiana Habruseva, Mikhail Sukhovei, Yuki Mitsufuji. ISMIR 2024.
-
This paper summarizes the cinematic demixing (CDX) track of the Sound Demixing Challenge 2023 (SDX’23). We provide a comprehensive summary of the challenge setup, detailing the structure of the competition and the datasets used.
-

High-Fidelity Lake Extraction via Two-Stage Prompt Enhancement: Establishing a Novel Baseline and Benchmark. Ben Chen, Xuechao Zou, Kai Li, Yu Zhang, Junliang Xing, Pin Tao ICME 2024. Niagra Falls, Canada
-
This paper presents LEPrompter, a two-stage prompt-based framework that enhances lake extraction from remote sensing imagery by using training prompts to improve segmentation accuracy and operating prompt-free during inference for efficient automated extraction.
-


An Audio-Visual Speech Separation Model Inspired by Cortico-Thalamo-Cortical Circuits. Kai Li, Fenghua Xie, Hang Chen, Kexin Yuan, Xiaolin Hu. TPAMI 2024.
-
A brain-inspired model for audio-visual speech separation. The state-of-the-art model on this task.
-
|

RTFS-Net: Recurrent time-frequency modelling for efficient audio-visual speech separation. Samuel Pegg*, Kai Li*, Xiaolin Hu. ICLR 2024. Vienna, Austria.
-
The core contribution of this paper is the development of the DiffCR framework, a novel fast conditional diffusion model for high-quality cloud removal from optical satellite images, which significantly outperforms existing models in both synthesis quality and computational efficiency.
-
|

DiffCR: A Fast Conditional Diffusion Framework for Cloud Removal From Optical Satellite Images. Xuechao Zou*, Kai Li*, Junliang Xing, Yu Zhang, Shiying Wang, Lei Jin, Pin Tao. TGRS 2024.
-
The core contribution of this paper is the development of the DiffCR framework, a novel fast conditional diffusion model for high-quality cloud removal from optical satellite images, which significantly outperforms existing models in both synthesis quality and computational efficiency.
-


Subnetwork-to-go: Elastic Neural Network with Dynamic Training and Customizable Inference. Kai Li, Yi Luo. ICASSP 2024. Seoul, Korea.
- A method for training neural networks with dynamic depth and width configurations, enabling flexible extraction of subnetworks during inference without additional training.

LEFormer: A Hybrid CNN-Transformer Architecture for Accurate Lake Extraction from Remote Sensing Imagery. Ben Chen, Xuechao Zou, Yu Zhang, Jiayu Li, Kai Li, Pin Tao. ICASSP 2024. Seoul, Korea.
-
The core contribution of this paper is the introduction of LEFormer, a hybrid CNN-Transformer architecture that effectively combines local and global features for high-precision lake extraction from remote sensing images, achieving state-of-the-art performance and efficiency on benchmark datasets.
-

2023

TDFNet: An Efficient Audio-Visual Speech Separation Model with Top-down Fusion. Samuel Pegg*, Kai Li*, Xiaolin Hu. ICIST 2023. Cairo, Egypt.
-
TDFNet is a cutting-edge method in the field of audio-visual speech separation. It introduces a multi-scale and multi-stage framework, leveraging the strengths of TDANet and CTCNet. This model is designed to address the inefficiencies and limitations of existing multimodal speech separation models, particularly in real-time tasks.
-


PMAA: A Progressive Multi-scale Attention Autoencoder Model for High-Performance Cloud Removal from Multi-temporal Satellite Imagery. Xuechao Zou*, Kai Li*, Junliang Xing, Pin Tao#, Yachao Cui. ECAI 2023. Kraków, Poland.
- A Progressive Multi-scale Attention Autoencoder (PMAA) model for high-performance cloud removal from multi-temporal satellite imagery, which achieves state-of-the-art performance on benchmark datasets.


An efficient encoder-decoder architecture with top-down attention for speech separation. Kai Li, Runxuan Yang, Xiaolin Hu. ICLR 2023. Kigali, Rwanda.
-
Top-down neural projections are ubiquitous in the brain. We found that this kind of projections are very useful for solving the Cocktail Party Problem.
-
-0084FF.svg) |
|


One-page Report for Tencent AI Lab’s CDX 2023 System. Kai Li, Yi Luo. SDX Workshop 2023. Paris, France.
- We present the system of Tencent AI Lab for the Cinematic Sound Demixing Challenge 2023, which is based on a novel neural network architecture and a new training strategy.

Audio-Visual Speech Separation in Noisy Environments with a Lightweight Iterative Model. Héctor Martel, Julius Richter, Kai Li, Xiaolin Hu and Timo Gerkmann. Interspeech 2023. Dublin, Ireland.
-
An audio-visual lightweight iterative model for speech separation in noisy environments. AVLIT employs Progressive Learning (PL) to decompose the mapping between inputs and outputs into multiple steps, enhancing computational efficiency.
-


A Neural State-Space Model Approach to Efficient Speech Separation. Chenchen, Chao-Han Huck Yang, Kai Li, Yuchen Hu, Pin-Jui Ku and Eng Siong Chng. Interspeech 2023. Dublin, Ireland.
-
We propose a Neural State-Space Model (S4M) for speech separation, which can efficiently separate multiple speakers.
-


On the Design and Training Strategies for RNN-based Online Neural Speech Separation Systems. Kai Li, Yi Luo. ICASSP 2023. Melbourne, Australia.
- The paper explores converting RNN-based offline neural speech separation systems to online systems with minimal performance degradation.
2022

On the Use of Deep Mask Estimation Module for Neural Source Separation Systems. Kai Li, Xiaolin Hu, Yi Luo. InterSpeech 2022. Incheon, Korea.
- We propose a Deep Mask Estimation Module for speech separation, which can improve the performance without additional computional complex.

Inferring mechanisms of auditory attentional modulation with deep neural networks Ting-Yu Kuo, Yuanda Liao, Kai Li, Bo Hong, Xiaolin Hu. Neural Computation, 2022.
-
With the help of DNNs, we suggest that the projection of top-down attention signals to lower stages within the auditory pathway of the human brain plays a more significant role than the higher stages in solving the “cocktail party problem”.
-

2021

Speech Separation Using an Asynchronous Fully Recurrent Convolutional Neural Network. Xiaolin Hu*, #, Kai Li$^*$, Weiyi Zhang, Yi Luo, Jean-Marie Lemercier, Timo Gerkmann. NeurIPS 2021. Online.
-
This paper introduces an asynchronous updating scheme in a bio-inspired recurrent neural network architecture, significantly enhancing speech separation efficiency and accuracy compared to traditional synchronous methods.
-
-0084FF.svg) |
| |
|

2020 and Prior

A Survey of Single Image Super Resolution Reconstruction. Kai Li, Shenghao Yang, Runting Dong, Jianqiang Huang#, Xiaoying Wang. IET Image Processing 2020.
- This paper provides a comprehensive survey of single image super-resolution reconstruction methods, including traditional methods and deep learning-based methods.

Single Image Super-resolution Reconstruction of Enhanced Loss Function with Multi-GPU Training. Jianqiang Huang*, #, Kai Li$^*$, Xiaoying Wang.
- This paper proposes a multi-GPU training method for single image super-resolution reconstruction, which can significantly reduce training time and improve performance.